为什么SAM可以实现更好的泛化?如何在Pytorch中实现SAM? |
您所在的位置:网站首页 › torch optimizer › 为什么SAM可以实现更好的泛化?如何在Pytorch中实现SAM? |
为什么SAM可以实现更好的泛化?如何在Pytorch中实现SAM?
|
导读 使用SAM(锐度感知最小化),优化到损失的最平坦的最小值的地方,增强泛化能力。 动机来自先前的工作,在此基础上,我们提出了一种新的、有效的方法来同时减小损失值和损失的锐度。具体来说,在我们的处理过程中,进行锐度感知最小化(SAM),在领域内寻找具有均匀的低损失值的参数。这个公式产生了一个最小-最大优化问题,在这个问题上梯度下降可以有效地执行。我们提出的实证结果表明,SAM在各种基准数据集上都改善了的模型泛化。 在深度学习中,我们使用SGD/Adam等优化算法在我们的模型中实现收敛,从而找到全局最小值,即训练数据集中损失较低的点。但等几种研究表明,许多网络可以很容易地记住训练数据并有能力随时overfit,为了防止这个问题,增强泛化能力,谷歌研究人员发表了一篇新论文叫做Sharpness Awareness Minimization,在CIFAR10上以及其他的数据集上达到了最先进的结果。 在本文中,我们将看看为什么SAM可以实现更好的泛化,以及我们如何在Pytorch中实现SAM。 SAM的原理是什么? 在梯度下降或任何其他优化算法中,我们的目标是找到一个具有低损失值的参数。但是,与其他常规的优化方法相比,SAM实现了更好的泛化,它将重点放在领域内寻找具有均匀的低损失值的参数(而不是只有参数本身具有低损失值)上。 由于计算邻域参数而不是计算单个参数,损失超平面比其他优化方法更平坦,这反过来增强了模型的泛化。
(左))用SGD训练的ResNet收敛到的一个尖锐的最小值。(右)用SAM训练的相同的ResNet收敛到的一个平坦的最小值。 注意:SAM不是一个新的优化器,它与其他常见的优化器一起使用,比如SGD/Adam。 在Pytorch中实现SAM 在Pytorch中实现SAM非常简单和直接 import torch class SAM(torch.optim.Optimizer): def __init__(self, params, base_optimizer, rho=0.05, **kwargs): assert rho 》= 0.0, f“Invalid rho, should be non-negative: {rho}” defaults = dict(rho=rho, **kwargs) super(SAM, self).__init__(params, defaults) self.base_optimizer = base_optimizer(self.param_groups, **kwargs) self.param_groups = self.base_optimizer.param_groups @torch.no_grad() def first_step(self, zero_grad=False): grad_norm = self._grad_norm() for group in self.param_groups: scale = group[“rho”] / (grad_norm + 1e-12) for p in group[“params”]: if p.grad is None: continue e_w = p.grad * scale.to(p) p.add_(e_w) # climb to the local maximum “w + e(w)” self.state[p][“e_w”] = e_w if zero_grad: self.zero_grad() @torch.no_grad() def second_step(self, zero_grad=False): for group in self.param_groups: for p in group[“params”]: if p.grad is None: continue p.sub_(self.state[p][“e_w”]) # get back to “w” from “w + e(w)” self.base_optimizer.step() # do the actual “sharpness-aware” update if zero_grad: self.zero_grad() def _grad_norm(self): shared_device = self.param_groups[0][“params”][0].device # put everything on the same device, in case of model parallelism norm = torch.norm( torch.stack([ p.grad.norm(p=2).to(shared_device) for group in self.param_groups for p in group[“params”] if p.grad is not None ]), p=2 ) return norm 代码取自非官方的Pytorch实现。 代码解释: 首先,我们从Pytorch继承优化器类来创建一个优化器,尽管SAM不是一个新的优化器,而是在需要继承该类的每一步更新梯度(在基础优化器的帮助下)。 该类接受模型参数、基本优化器和rho, rho是计算最大损失的邻域大小。 在进行下一步之前,让我们先看看文中提到的伪代码,它将帮助我们在没有数学的情况下理解上述代码。
正如我们在计算第一次反向传递后的伪代码中看到的,我们计算epsilon并将其添加到参数中,这些步骤是在上述python代码的方法first_step中实现的。 现在在计算了第一步之后,我们必须回到之前的权重来计算基础优化器的实际步骤,这些步骤在函数second_step中实现。 函数_grad_norm用于返回矩阵向量的norm,即伪代码的第10行 在构建这个类后,你可以简单地使用它为你的深度学习项目通过以下的训练函数片段。 from sam import SAM 。。. model = YourModel() base_optimizer = torch.optim.SGD # define an optimizer for the “sharpness-aware” update optimizer = SAM(model.parameters(), base_optimizer, lr=0.1, momentum=0.9) 。。. for input, output in data: # first forward-backward pass loss = loss_function(output, model(input)) # use this loss for any training statistics loss.backward() optimizer.first_step(zero_grad=True) # second forward-backward pass loss_function(output, model(input)).backward() # make sure to do a full forward pass optimizer.second_step(zero_grad=True) 。。. 总结 虽然SAM的泛化效果较好,但是这种方法的主要缺点是,由于前后两次计算锐度感知梯度,需要花费两倍的训练时间。除此之外,SAM还在最近发布的NFNETS上证明了它的效果,这是ImageNet目前的最高水平,在未来,我们可以期待越来越多的论文利用这一技术来实现更好的泛化。 英文原文:https://pub.towardsai.net/we-dont-need-to-worry-about-overfitting-anymore-9fb31a154c81 编辑:lyn SAM SAM +关注关注 0文章 42浏览量 31716 深度学习 深度学习 +关注关注 70文章 3995浏览量 112060 pytorch pytorch +关注关注 1文章 121浏览量 10602原文标题:【过拟合】再也不用担心过拟合的问题了 文章出处:【微信号:zenRRan,微信公众号:深度学习自然语言处理】欢迎添加关注!文章转载请注明出处。 收藏 人收藏扫一扫,分享给好友 复制链接分享 评论发布评论请先 登录 相关推荐 让AI应用程序为本机云做好准备 Fleet Command 将应用程序部署为容器。通过使用容器,您可以在同一系统上部署多个应用程....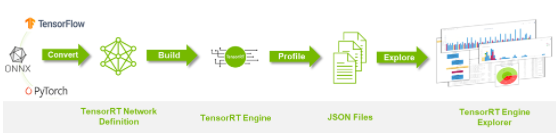 5种前沿的点云分割网络
整体的PointNet网络中,除了点云的感知以外,还有T-Net,即3D空间变换矩阵预测网络,这主要....
5种前沿的点云分割网络
整体的PointNet网络中,除了点云的感知以外,还有T-Net,即3D空间变换矩阵预测网络,这主要....
 Jittor(计图)即时编译深度学习框架
./oschina_soft/gitee-jittor.zip
发表于 06-21 10:33 •
5次
阅读
MegEngine(天元)深度学习框架
./oschina_soft/MegEngine.zip
发表于 06-21 10:32 •
3次
阅读
一种新方法GSConv来减轻模型的复杂度并保持准确性
类脑研究的直观理解是,神经元越多的模型获得的非线性表达能力越强。但不可忽视的是,生物大脑处理信息的强....
Clause语义理解系统
./oschina_soft/clause.zip
发表于 06-21 09:55 •
1次
阅读
Paddle Lite飞桨多平台高性能深度学习预测引擎
./oschina_soft/gitee-paddle-lite.zip
发表于 06-21 09:43 •
3次
阅读
开源软件-DLPack开放的内存张量结构
./oschina_soft/dlpack.zip
发表于 06-21 09:26 •
7次
阅读
Transformer模型结构,训练过程
所以我们为此文章写了篇注解文档,并给出了一行行实现的Transformer的代码。本文档删除了原文的....
开源软件-OneFlow通用深度学习框架
./oschina_soft/oneflow.zip
发表于 06-20 09:26 •
10次
阅读
基于深度学习的边缘计算服务器助力AI人工智能
随着深度学习、医药研发、生命科学、遥感测绘、高性能计算、数据研发、数据挖掘的快速发展,基于人工智能的....
Jittor(计图)即时编译深度学习框架
./oschina_soft/gitee-jittor.zip
发表于 06-21 10:33 •
5次
阅读
MegEngine(天元)深度学习框架
./oschina_soft/MegEngine.zip
发表于 06-21 10:32 •
3次
阅读
一种新方法GSConv来减轻模型的复杂度并保持准确性
类脑研究的直观理解是,神经元越多的模型获得的非线性表达能力越强。但不可忽视的是,生物大脑处理信息的强....
Clause语义理解系统
./oschina_soft/clause.zip
发表于 06-21 09:55 •
1次
阅读
Paddle Lite飞桨多平台高性能深度学习预测引擎
./oschina_soft/gitee-paddle-lite.zip
发表于 06-21 09:43 •
3次
阅读
开源软件-DLPack开放的内存张量结构
./oschina_soft/dlpack.zip
发表于 06-21 09:26 •
7次
阅读
Transformer模型结构,训练过程
所以我们为此文章写了篇注解文档,并给出了一行行实现的Transformer的代码。本文档删除了原文的....
开源软件-OneFlow通用深度学习框架
./oschina_soft/oneflow.zip
发表于 06-20 09:26 •
10次
阅读
基于深度学习的边缘计算服务器助力AI人工智能
随着深度学习、医药研发、生命科学、遥感测绘、高性能计算、数据研发、数据挖掘的快速发展,基于人工智能的....
 基于深度学习的水冷工作站加速遥感测绘应用研发
在深度学习、高性能计算、大数据、计算机电子技术、图像渲染、视觉计算快速发展的大背景下,地质遥感技术脱....
基于深度学习的水冷工作站加速遥感测绘应用研发
在深度学习、高性能计算、大数据、计算机电子技术、图像渲染、视觉计算快速发展的大背景下,地质遥感技术脱....
 AKG深度学习网络优化程序
./oschina_soft/gitee-akg.zip
发表于 06-17 14:50 •
3次
阅读
Kaolin加速3D深度学习研究
./oschina_soft/kaolin.zip
发表于 06-17 11:18 •
9次
阅读
OpenPPL高性能深度学习推理平台
./oschina_soft/ppl.nn.zip
发表于 06-17 11:16 •
13次
阅读
WeChat TFCC微信云端深度学习推理框架
./oschina_soft/WeChat-TFCC.zip
发表于 06-17 10:31 •
5次
阅读
APACHE MXNET深度学习框架的概念、工作原理及用例
Apache MXNet 是一个灵活且可扩展的深度学习框架,支持多种深度学习模型、编程语言,并且有一....
PatrickStar分布式深度学习训练工具
./oschina_soft/PatrickStar.zip
发表于 06-16 11:06 •
7次
阅读
Adlik加速深度学习推理的工具包
./oschina_soft/Adlik.zip
发表于 06-16 10:19 •
6次
阅读
DLVC基于深度学习的视频编码
./oschina_soft/DLVC.zip
发表于 06-16 09:26 •
3次
阅读
三步骤快速实现PaddleOCR实时推理
前言:该技术能让PaddleOCR的开发者在笔记本电脑上即可获得超越40FPS的速度,极大降低了Pa....
AKG深度学习网络优化程序
./oschina_soft/gitee-akg.zip
发表于 06-17 14:50 •
3次
阅读
Kaolin加速3D深度学习研究
./oschina_soft/kaolin.zip
发表于 06-17 11:18 •
9次
阅读
OpenPPL高性能深度学习推理平台
./oschina_soft/ppl.nn.zip
发表于 06-17 11:16 •
13次
阅读
WeChat TFCC微信云端深度学习推理框架
./oschina_soft/WeChat-TFCC.zip
发表于 06-17 10:31 •
5次
阅读
APACHE MXNET深度学习框架的概念、工作原理及用例
Apache MXNet 是一个灵活且可扩展的深度学习框架,支持多种深度学习模型、编程语言,并且有一....
PatrickStar分布式深度学习训练工具
./oschina_soft/PatrickStar.zip
发表于 06-16 11:06 •
7次
阅读
Adlik加速深度学习推理的工具包
./oschina_soft/Adlik.zip
发表于 06-16 10:19 •
6次
阅读
DLVC基于深度学习的视频编码
./oschina_soft/DLVC.zip
发表于 06-16 09:26 •
3次
阅读
三步骤快速实现PaddleOCR实时推理
前言:该技术能让PaddleOCR的开发者在笔记本电脑上即可获得超越40FPS的速度,极大降低了Pa....
 Animegan2-pytorch图片/视频转动漫风格
./oschina_soft/animegan2-pytorch.zip
发表于 06-07 14:35 •
17次
阅读
共聚、共研、共创,飞桨联合国内外硬件伙伴构建软硬一体智能化全新生态
百度AI技术生态总经理马艳军表示,飞桨将联合硬件生态伙伴,通过技术的联合研发和生态共建,一起开拓出更....
Animegan2-pytorch图片/视频转动漫风格
./oschina_soft/animegan2-pytorch.zip
发表于 06-07 14:35 •
17次
阅读
共聚、共研、共创,飞桨联合国内外硬件伙伴构建软硬一体智能化全新生态
百度AI技术生态总经理马艳军表示,飞桨将联合硬件生态伙伴,通过技术的联合研发和生态共建,一起开拓出更....
 很好的一本书,适合初学者
发表于 06-05 18:49 •
3702次
阅读
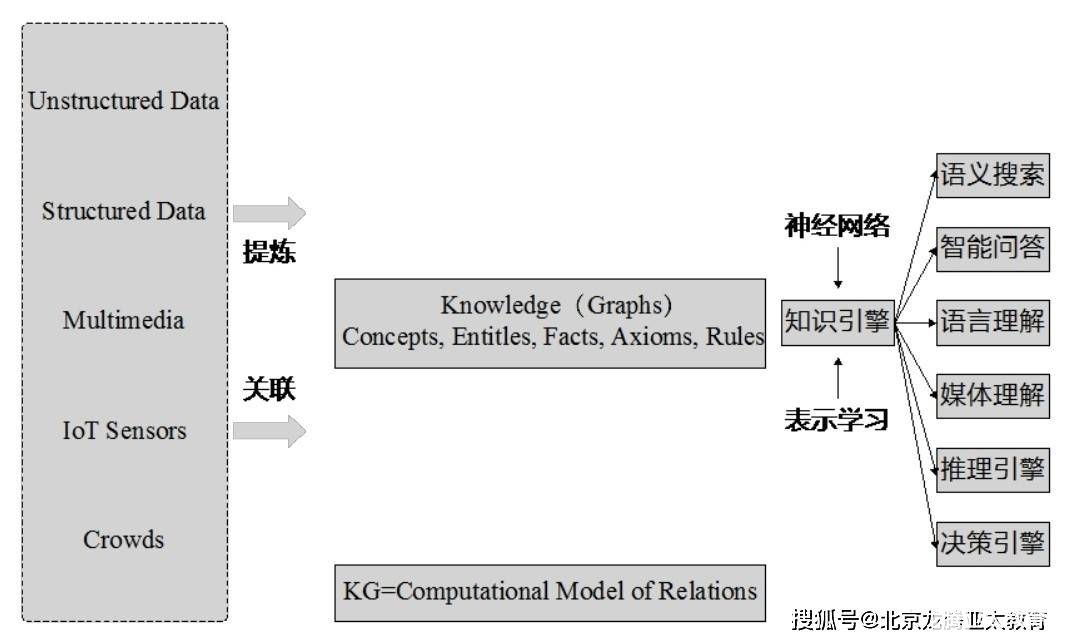
什么是知识图谱?人工智能世界知识图谱的发展
1.1 什么是知识图谱 知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法[....
很好的一本书,适合初学者
发表于 06-05 18:49 •
3702次
阅读
什么是知识图谱?人工智能世界知识图谱的发展
1.1 什么是知识图谱 知识图谱是一种用图模型来描述知识和建模世界万物之间的关联关系的技术方法[....
 PolyFun生成Low Poly风格图片
./oschina_soft/PloyFun.zip
发表于 05-31 14:28 •
8次
阅读
KITTI 3D检测数据集
因为gt label中提供的bbox信息是Camera坐标系的,因此在训练时需要使用外参等将其转换到....
SwinIR图片修复工具
./oschina_soft/SwinIR.zip
发表于 05-30 10:34 •
31次
阅读
基于AI的实时感知提升自动代客泊车功能
PSA 系统在 NVIDIA DRIVE AGX 上运行仅几毫秒,就可以以惊人的准确性实现复杂的....
PolyFun生成Low Poly风格图片
./oschina_soft/PloyFun.zip
发表于 05-31 14:28 •
8次
阅读
KITTI 3D检测数据集
因为gt label中提供的bbox信息是Camera坐标系的,因此在训练时需要使用外参等将其转换到....
SwinIR图片修复工具
./oschina_soft/SwinIR.zip
发表于 05-30 10:34 •
31次
阅读
基于AI的实时感知提升自动代客泊车功能
PSA 系统在 NVIDIA DRIVE AGX 上运行仅几毫秒,就可以以惊人的准确性实现复杂的....
 MMOCR基于PyTorch的文本检测工具
./oschina_soft/mmocr.zip
发表于 05-30 09:43 •
27次
阅读
深度学习模型转成TensorRT引擎的流程
前面我们花了很多力气在 TAO 上面训练模型,其最终目的就是要部署到推理设备上发挥功能。除了将模型训....
deoplete.nvim Neovim异步完成框架
./oschina_soft/deoplete.nvim.zip
发表于 05-24 09:52 •
19次
阅读
C#平台调用OpenVINO的可行性
OpenVINO 工具套件是英特尔基于自身现有的硬件平台开发的一种可以加快高性能计算机视觉和深度学习....
MMOCR基于PyTorch的文本检测工具
./oschina_soft/mmocr.zip
发表于 05-30 09:43 •
27次
阅读
深度学习模型转成TensorRT引擎的流程
前面我们花了很多力气在 TAO 上面训练模型,其最终目的就是要部署到推理设备上发挥功能。除了将模型训....
deoplete.nvim Neovim异步完成框架
./oschina_soft/deoplete.nvim.zip
发表于 05-24 09:52 •
19次
阅读
C#平台调用OpenVINO的可行性
OpenVINO 工具套件是英特尔基于自身现有的硬件平台开发的一种可以加快高性能计算机视觉和深度学习....
|

【本文地址】